
Thirty-two copies of a language model were training on a single sixteen-core box. Every twenty-nine seconds, on a schedule, something went wrong on purpose: a process kill -9‘d out of existence, or frozen mid-step with a SIGSTOP, or cut off from the network entirely. Over half an hour, twenty-seven of them were killed outright — and partitioned, and stalled, sixty-two faults in all. Nobody touched a keyboard. At the end, the model’s loss had fallen 10.8 → 4.3 in a clean monotonic descent, and the cluster had retained 97.7% of the throughput it would have had if nothing ever broke.
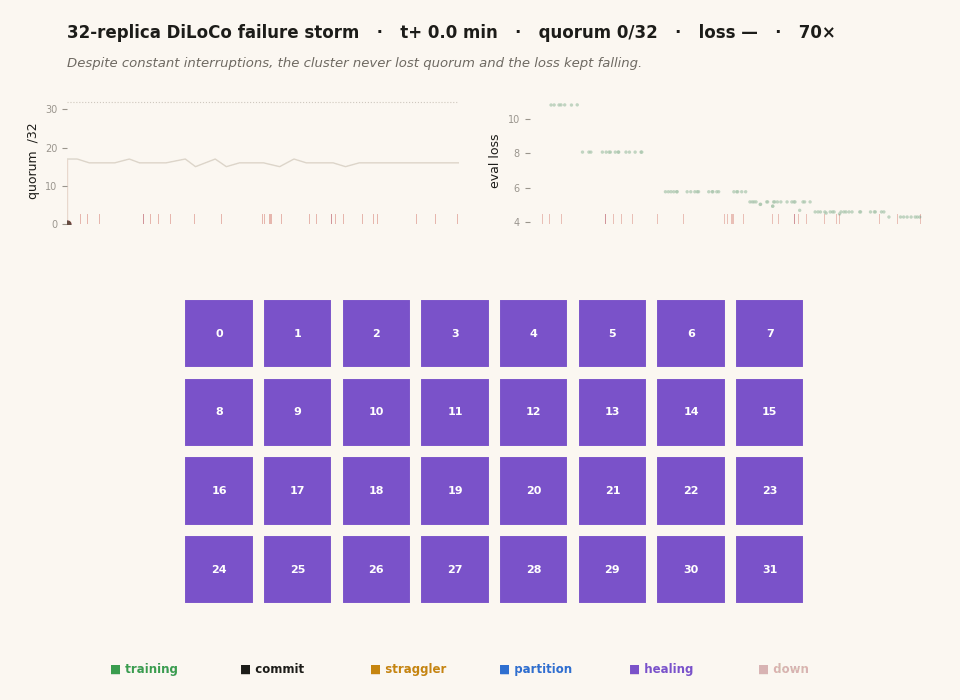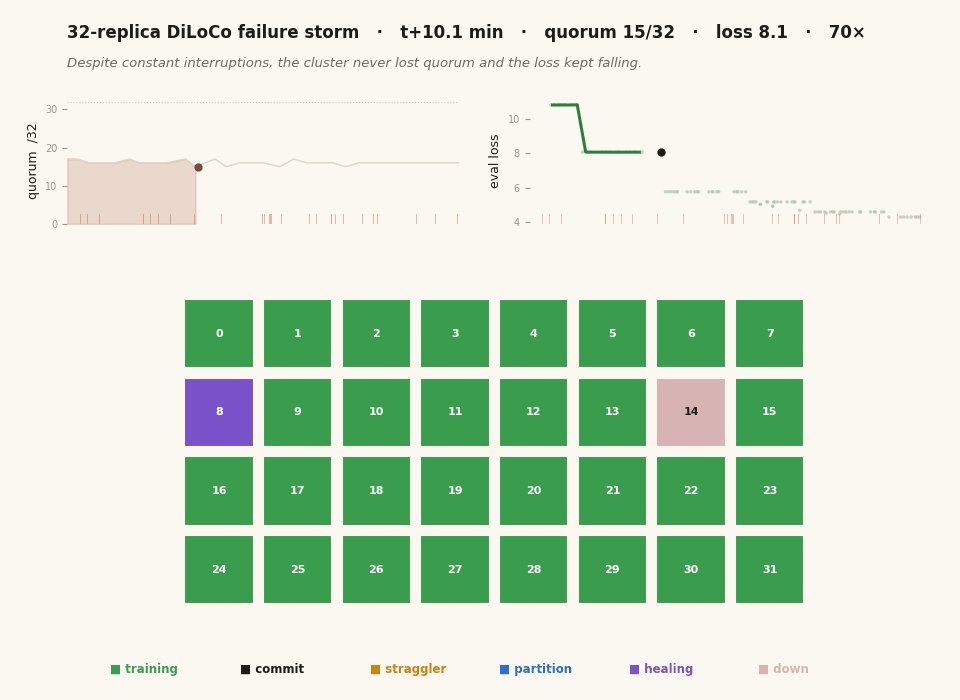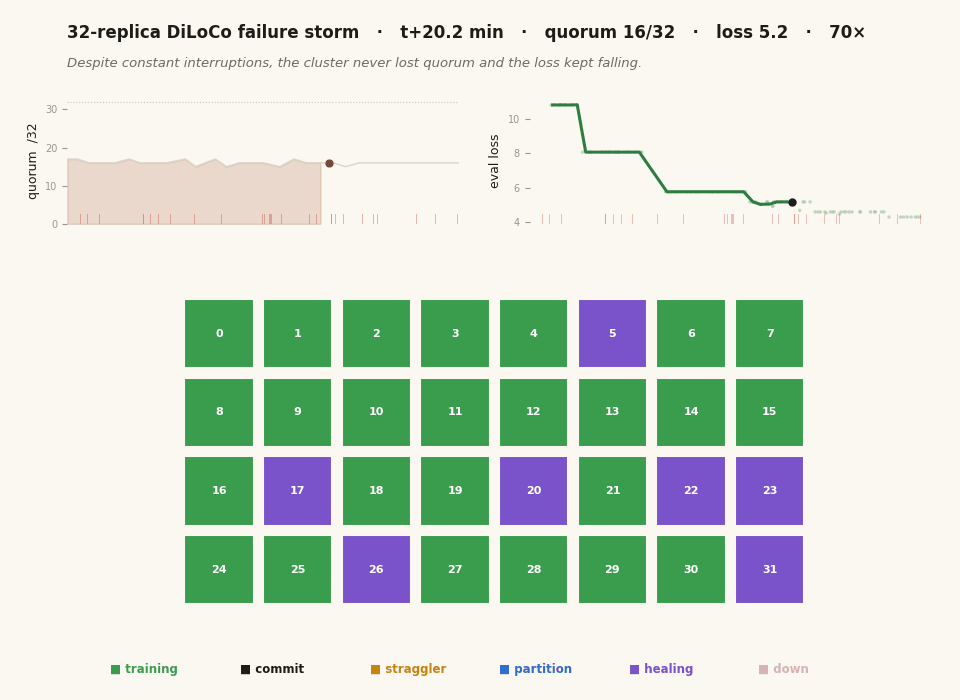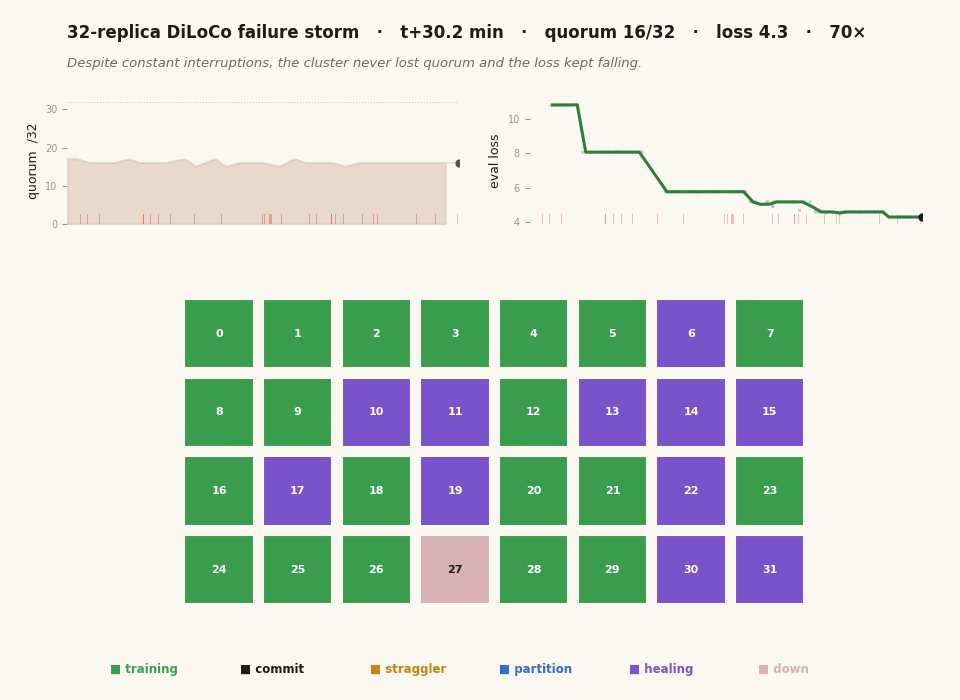
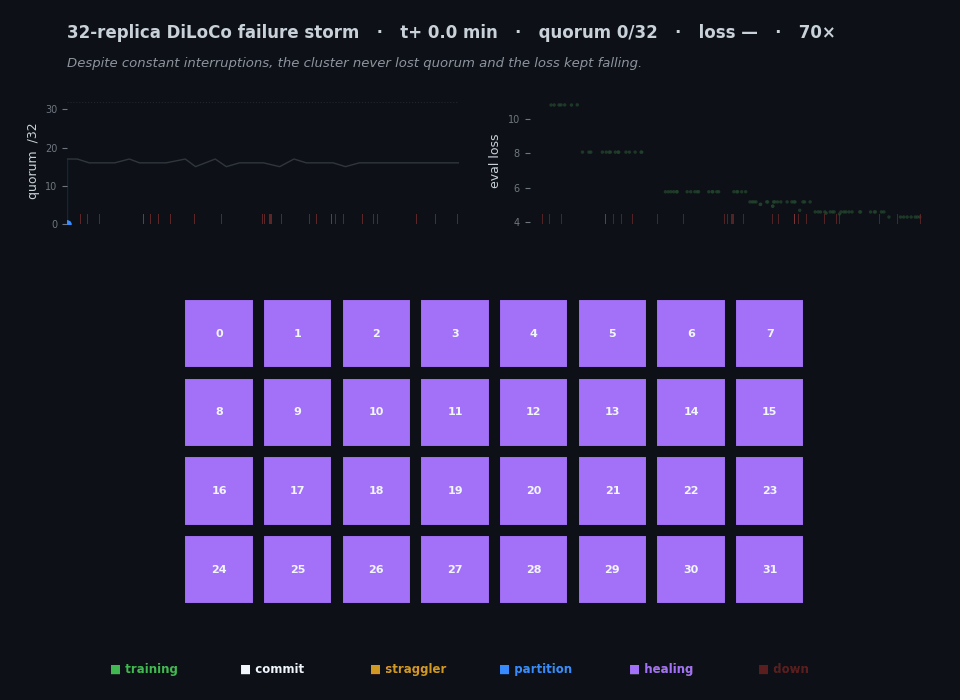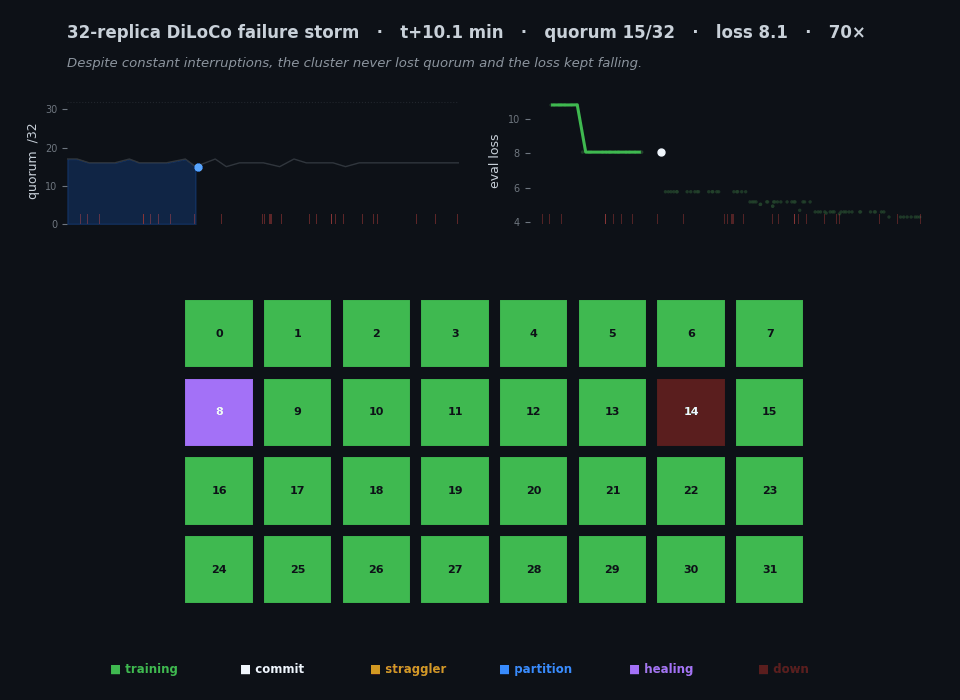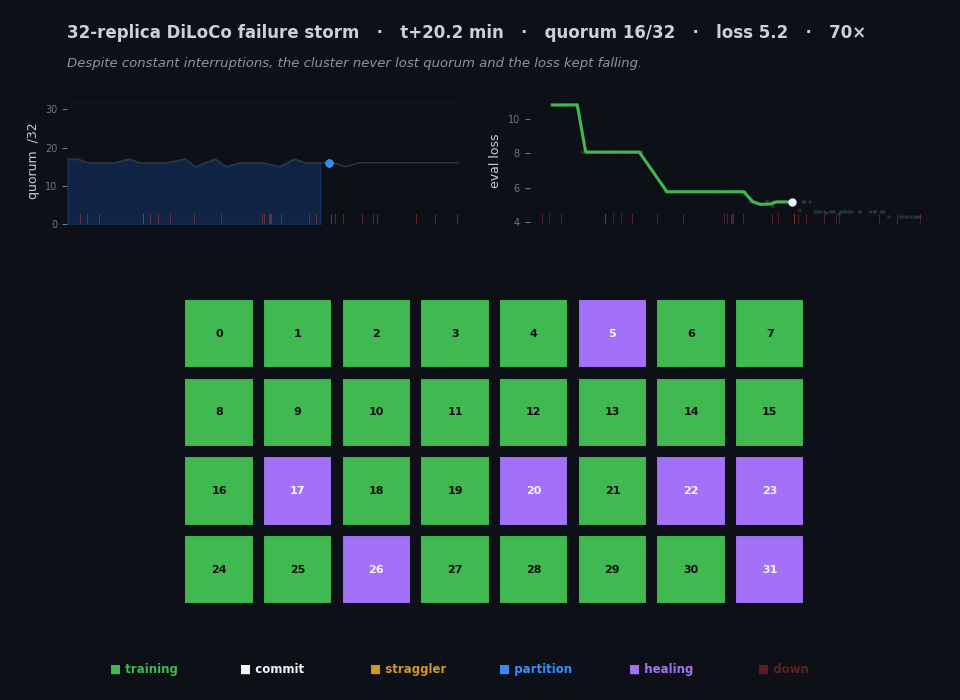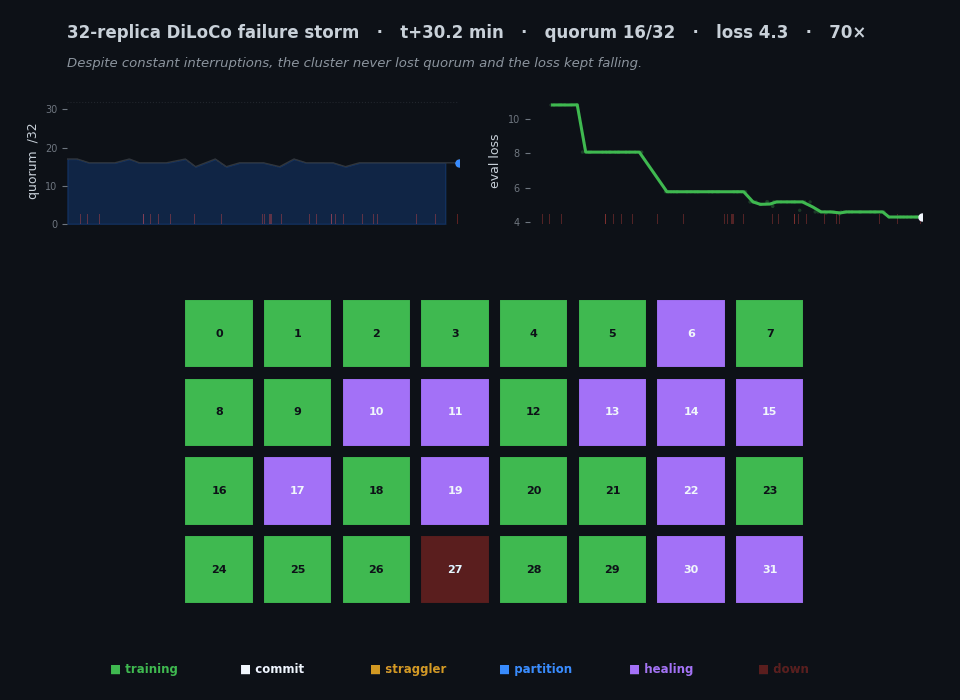
The whole project in twenty-six seconds. Each cell is one of 32 replica groups, colored by what it's doing — training, committing a sync, killed, frozen, partitioned, or healing back from a peer. The left chart tracks the live quorum, the right chart the eval loss, and the red ticks mark every kill. Thirty minutes of real wall-clock is compressed here; the animation isn't a screen recording but a reconstruction from the timestamped JSONL each replica wrote, which is why the time axis and the encoding are mine to choose. The thing to watch is that the chaos on the grid never stops the loss on the right from falling. (This figure ships in two renders — one tuned for each — and swaps with the light/dark toggle at the top of the page.)
That this works at all is the easy part of the story, and it isn’t mine — it’s DiLoCo and Meta’s torchft. The interesting part is what you have to discover to make it work honestly. torchft’s headline result is fault tolerance at the scale you’d expect it: ~300 production GPUs, a real training job, machines failing about once a minute. The question that started this project was smaller and more suspicious — does any of that survive on the kind of hardware you’d actually scrounge? A gaming GPU, a couple of old boxes, a home network you can throttle to a crawl.
The answer is yes, but the yes comes with two distinctions I didn’t have words for when I started, and that turned out to be the project:
- Connectivity ≠ coordination. Two machines that can reach each other are not therefore training together. I watched a “cluster” silently dissolve into independent solo runs while every node reported perfect health.
- Liveness ≠ participation. At scale, “alive” and “contributing to this sync” are different numbers, and the gap between them is a real, measurable tax that no dashboard was showing me.
This is the build log of getting there — across six milestones, on a 16-core Ryzen box, an 8-core machine, and about three dollars of rented cloud — including the run where the loss regressed while every throughput metric looked perfect, which is the actual research finding buried in here.
I’ll be disciplined about provenance, because distributed-systems claims oversell as easily as benchmark numbers. Every load-bearing figure below is tagged: measured (read directly from a run’s telemetry), derived (composed from measured primitives), or single-run (a one-shot result I haven’t repeated — the cloud experiments, mostly). There’s a full ledger near the end. The animation above, and every chart in this post, is reconstructed from the JSONL each run wrote — the timestamps are the ground truth.
What This Post Covers
- Why you’d train a model with rare syncs at all — the assumption baked into normal distributed training, and the one DiLoCo relaxes to make commodity hardware viable.
- What torchft actually guarantees — quorum, peer-to-peer recovery, commit/rollback — and the open question it leaves, which is the one I set out to answer empirically: does the outer optimizer’s momentum survive a machine leaving and coming back?
- The six-milestone build, with the negative results kept in — the silent eval-loss regression, the cluster that dissolved over a healthy network, and the participation ceiling that turned out to be a CPU-scheduling artifact.
- The honest ledger — what I measured, what I derived, and what’s a single un-repeated run.
This post assumes you know roughly what it means to train a neural network with gradient descent. It does not assume you know what DiLoCo, a quorum, or an all-reduce is — we’ll build those up. If you do distributed training for a living, skim Part I.
Part I — Why Train This Way at All
The expensive-cluster assumption
The default way to train a model on many machines is data-parallel: every machine holds a full copy of the model, each processes a different slice of the batch, and after every single step they average their gradients so all copies stay identical. That average is an all-reduce — every machine sends its gradient to every other, billions of numbers, hundreds of times a second.
This is why “distributed training” is a synonym for “expensive interconnect.” Syncing every step only makes sense if the network between your machines is nearly as fast as the memory inside them — NVLink, InfiniBand, a datacenter fabric. The moment your machines are connected by something ordinary — an office LAN, the open internet, a home router — per-step syncing collapses, because the machines spend all their time waiting on the wire instead of computing.
DiLoCo’s move is to relax when you synchronize, not just how much. Each worker trains entirely on its own for H steps — a hundred, five hundred — using a normal inner optimizer (AdamW). Only then do the workers compare notes, and what they exchange isn’t a per-step gradient but a pseudo-gradient: the total drift of each worker’s parameters over those H steps. A second, outer optimizer (Nesterov-momentum SGD) treats that averaged drift as a single gradient and takes one big step. Then everyone broadcasts the updated weights and runs another H steps alone.
The DiLoCo loop. Each replica runs H inner AdamW steps with no communication at all, then the replicas exchange one number per parameter — the pseudo-gradient Δ, the drift over those H steps — average it, and the outer Nesterov optimizer takes a single step on that average before broadcasting the new weights. The communication that data-parallel training does every step happens here once every H steps, so the wire traffic drops by roughly a factor of H. The price is that the workers diverge for H steps before being pulled back together, and the quality of the final model depends on H and the outer learning rate. That this trade is *smooth* — that you can dial H up and watch quality degrade gracefully — is what makes it a knob rather than a cliff, and Part II measures exactly where it bends.
The consequence is the whole reason this is interesting on cheap hardware: communication drops by roughly a factor of H. If you sync every 100 steps instead of every step, you move ~100× less data. Suddenly a home gigabit link — or a 50 Mbps DSL connection, or the open internet between two cities — is fast enough to train collaboratively. And because the syncs are rare and coarse, the system can tolerate a worker vanishing between them, which is where fault tolerance comes in.
What torchft adds, and the question it leaves open
DiLoCo is an algorithm; you still need machinery to run it across machines that fail. That’s torchft. It contributes three things. A lighthouse — a small coordinator process — tracks which workers are alive and forms a quorum (the set of workers participating in a given sync). Each worker runs a manager that handles the membership protocol. When a worker dies and a replacement starts, torchft does peer-to-peer recovery: the newcomer pulls the current model state directly from a living peer, no shared checkpoint required. And every sync is a commit/rollback transaction — if a worker drops mid-sync, the others roll back cleanly rather than corrupting the average.
The torchft team demonstrated this at scale: a Llama-3 1B model, ~300 L40S GPUs in 30 replica groups, a failure injected roughly once a minute, sustaining 82.3% step efficiency through it. That’s the number to beat — or rather, to see whether anything like it holds three orders of magnitude down the hardware ladder.
There’s a specific open question underneath all this, raised in torchft’s own issue #171 on semi-synchronous training. DiLoCo’s outer optimizer has momentum — a running memory of past pseudo-gradients, essential to convergence. When a worker is killed and rebuilt from a peer, does it recover that outer-optimizer momentum exactly, or does recovery quietly reset it and degrade the run? Peer-to-peer recovery of model weights is one thing; bit-exact recovery of optimizer state through a real kill -9 is the empirical question I most wanted to answer, because if it doesn’t hold, none of the rest matters. (torchft is moving fast; I pinned commit 4157be16 for every run here so the numbers are reproducible.)
The rig
Everything below runs on deliberately ordinary hardware: a Ryzen 9 5950X with a single RTX 3060 (12 GB) as the GPU trainer, an 8-core box as the lighthouse, gigabit home ethernet with tc/netem standing in for a worse WAN, and — for the two cross-region experiments — about $3 of rented cloud. The model is a small GPT (51M parameters for the convergence work, a 3.3M “micro” model for the largest-scale chaos) trained on TinyStories. None of this is a cluster. That’s the point.
Part II — Building It, One Honest Measurement at a Time
M0 — A baseline, and a memory surprise
You cannot claim fault tolerance preserves quality without a quality bar to compare against, so the first run was the most boring possible: a single GPU, no faults, three random seeds. The 51M model settles at an eval loss of 1.6773 ± 0.0009 — tight enough across seeds that any later degradation will be visible against it. [measured]
The only surprise here was a memory one, and it’s worth a sentence because it bites everyone once. The first training run OOM’d at a batch size the GPU should have handled with room to spare. The culprit wasn’t the weights — it was the cross-entropy loss over a 50,000-token vocabulary, which briefly materializes a logits tensor of batch × sequence × vocab floats. The model is tiny; its output distribution is enormous. The fix was a micro-batch with gradient accumulation, but the lesson generalizes: in a language model, profile the loss, not just the parameters.
M0.5 — Does any of this actually work on my hardware?
Before building anything elaborate, I wanted the Part I question answered on the real rig: kill a worker mid-training and see what survives. Two replicas, training; then kill -9 on one. The survivor’s next sync committed 5.0 seconds later with the quorum cleanly shrunk from two to one — no stall, no manual intervention. The killed worker was relaunched, and torchft logged exactly what I’d hoped: healing is required, then a peer-to-peer state transfer from the survivor. 54 seconds after the kill it had rejoined and committed as a full member again — most of that time process and CUDA startup, not the transfer itself. [measured]
A single kill-and-recover, the mechanism the whole project rests on. Replica B is killed mid-run; the quorum shrinks two-to-one and the survivor (A) keeps committing solo — fault tolerance means the cluster doesn't wait for the dead. When B is relaunched it doesn't restart from scratch: it pulls the live model state directly from A over a peer-to-peer transfer and rejoins at the cluster's current step. The number that mattered to me is the one in the box: I logged a SHA-256 digest of the parameters *and* the outer Nesterov momentum at every post-recovery sync, and every single one matched bit-for-bit across both replicas. The outer optimizer's momentum — the thing issue #171 worries about — survives a real `kill -9` exactly, with no checkpoint involved. That's the foundation; if this digest hadn't matched, nothing later would be trustworthy.
The headline from M0.5 is that box: at every sync after recovery, I logged a digest of the parameters and the outer momentum buffers, and they were bit-identical across replicas, every time. The outer optimizer’s momentum survives a kill-and-rejoin through live recovery alone — no durable checkpoint needed. That’s the #171 question answered in the affirmative, at least in the easy regime of a single failure with a healthy survivor. (M3 will find the regime where “a healthy survivor” stops being a safe assumption.)
A footnote for anyone trying this: torchft’s standalone path has sharp edges that aren’t well documented. The manager hard-requires torchrun-style environment variables and a TCPStore it expects something else to host; run it bare and it blocks forever with no error. I ended up hosting the store myself and steering around a couple of known live bugs (use_async_quorum=False, HTTP transport for recovery). Reproducing this on your own hardware is very doable, but budget an afternoon for the plumbing.
M1 — Parity, and the communication win
With recovery proven, the next question is the core DiLoCo trade: how much quality do you give up for syncing rarely, and how much communication do you actually save? I ran a sweep — sync every H = 25, 50, 100, 200, 500 steps — against the M0 baseline at equal total tokens.
| sync every H steps | eval loss | vs baseline | communication |
|---|---|---|---|
| 25 | 1.724 | +2.8% | 25× less |
| 50 | 1.756 | +4.7% | 50× less |
| 100 | 1.783 | +6.3% | 100× less |
| 200 | 1.801 | +7.4% | 200× less |
| 500 | 1.836 | +9.4% | 500× less |
The trade is smooth and monotonic, exactly as DiLoCo’s authors found — which is what makes H a usable dial. [measured; single seed per H, and the outer learning rate is left untuned across H, which honestly favors small H — a per-H tune would flatten the right end of this curve.] The communication reduction is exact: H = 100 really does move 100× fewer bytes.
Communication volume per replica over a whole run, on a log scale. The red bars are what data-parallel training would have cost on the same model — sync every step — and they tower over everything, flat across H because per-step syncing doesn't care how you've set H. The brown bars are DiLoCo's analytic cost, dropping by exactly the factor labeled above each pair: 25×, 50×, on up to 500×. The third bar in each group is what I actually measured off the virtual ethernet counters, and it tracks the analytic number to within a few percent — except the gap widens at large H, which is the tell. That residual is a roughly constant ~0.5 GB-per-run floor of control-plane chatter — the lighthouse heartbeats and quorum messages — that only becomes visible once the pseudo-gradient payload itself shrinks small enough to stop dominating. It's a reminder that "communication" in a fault-tolerant system isn't only the data plane; there's a coordinator quietly talking the whole time.
The measured bytes track the analytic prediction within a few percent — until H gets large, where a constant ~0.5 GB-per-run floor of lighthouse heartbeats and quorum traffic starts to show through. It never matters for the data plane, but it foreshadows M4, where that same control-plane traffic becomes the thing that breaks.
M2 — The money shot: killing a node on camera
M0.5 proved recovery works; M2 was about proving it works under a scripted sequence of real faults, and instrumenting it well enough to put numbers on recovery. I built a small chaos harness that injects genuine OS-level faults — not cooperative shutdowns but actual kill -9, SIGSTOP for stragglers, and link-down via iptables for partitions — each one logged with a timestamp to a ground-truth chaos.jsonl. A six-fault scenario (kill, relaunch, partition, heal, stall a straggler, resume) ran headless and finished within +0.6% of the fault-free loss, with 84 of 84 post-recovery digests matching. [measured]
The lesson I took from M2 is one I keep relearning: the demo is half the deliverable. A claim that “fault tolerance works” is worth far less than a recording of a node dying and the system shrugging it off, and building the telemetry to reconstruct that recording faithfully — every fault and commit timestamped — is what later let me animate a thirty-two-node storm from data alone, with no live screen-capture at all.
M3 — Failure storms, and the negative result that’s the actual research
Single scripted faults are a warm-up. A real test is a storm: faults arriving on a Poisson schedule, a supervisor automatically relaunching the dead, no human in the loop, for forty-five minutes straight. I ran two — one averaging a kill every 120 seconds, one every 60 — and measured step efficiency the way torchft does: committed training steps per second under chaos, as a fraction of the fault-free rate.
Step efficiency under two failure storms, against the references that matter. The dashed line at the top is fault-free throughput — the ceiling. The dashed line at 82.3% is torchft's published large-scale result on 300 GPUs, the number I most wanted to not embarrass myself against. Both of my storms — 69 and 85 executed faults per hour, heavier fault rates than the reference, on two consumer replicas — clear it: 88.2% and 85.0% of fault-free throughput. I want to be careful about what this does and doesn't claim. It is not "commodity hardware beats a datacenter," because the workloads and scales are completely different; it's that the *coordination machinery* doesn't fall apart at small scale, and that the efficiency cost of a fault is comparable. The throughput story, in other words, looked great. Which is exactly why the next figure matters.
Both storms cleared 85% — above torchft’s large-scale bar, at higher fault rates, on two consumer replicas. [derived: committed-step rate under chaos ÷ the fault-free M1 rate.] I was ready to call M3 a win on the strength of that number. Then I looked at the eval loss.
The most important figure in this post, and the one I almost didn't make. The red curve is the eval loss during a storm where throughput read a healthy 87% the entire time — and the model is getting *worse*, oscillating up toward 4.0 after having reached 2.4. The system was committing syncs at a great rate; the syncs were poisoning the model. The mechanism is subtle and specific to small replica counts: a kill landing while the only other member is alive-but-not-yet-healed leaves a freshly-restarted worker as a one-member quorum, and that worker's near-random initial weights silently *become* the cluster's official state — I caught the survivors healing from a donor at step zero. Live peer-to-peer recovery, the thing M0.5 proved works, is necessary but not sufficient under restart churn. The brown curve is the same storm after the fix: each replica also persists state every few commits, so a wiped quorum resumes from durable ground truth instead of from noise, and a kill is only ever injected when a *healthy* donor exists. The loss descends and holds. Throughput was never the thing to watch.
This is the research result, and it’s a negative one I’m glad I kept. Throughput is a seductive metric because it’s always green: as long as syncs are committing, the dashboard looks healthy. But a sync can commit the wrong thing. At small replica counts, a kill that lands while the cluster’s only other member hasn’t finished healing leaves a fresh-init worker alone in a quorum, and torchft faithfully makes that worker’s random weights the official state — the survivors then “recover” from step zero. Throughput stayed at 87%; the model rotted from 2.4 back up toward 4.0.
The fix has two parts: commit-coupled checkpoints (each replica also persists durable state every few commits, so a wiped quorum resumes from real progress instead of noise) and an experiment-hygiene rule that a kill only fires when a healthy, recently-committed donor exists. With both in place, the second run’s loss descended monotonically and held. torchft’s 30-group setup makes this failure mode practically unreachable — but the cross-datacenter, few-big-members regime that #171 is actually about hits it head-on, which is why it’s worth documenting rather than patching over.
M4 — The WAN, and “connectivity ≠ coordination”
Everything so far ran on a fast LAN. The premise of the whole project is unreliable, slow links, so M4 made the network bad on purpose with netem, then made it real with rented cloud.
Throughput as the link degrades from gigabit down to 10 Mbps, at a fixed 20 ms of latency. The lower curve is per-step syncing (data-parallel's communication pattern): even at gigabit it's already paying ~2 seconds per step to move the model, and it falls off a cliff as bandwidth shrinks. The upper curve is DiLoCo at H = 100 — flat across two orders of magnitude of bandwidth, because it amortizes that same transfer over a hundred local steps. The shaded zone on the left is where both die, and *how* they die is the interesting part: at 10 Mbps the ~200-second pseudo-gradient all-reduce so completely saturates the link that the lighthouse's own heartbeats can't get through, the quorum times out mid-transfer, and the cluster cascades into failure. The data plane starved the control plane — the same ~0.5 GB of coordinator chatter from the M1 figure, now fatal because it's competing for a pipe that's already full. The documented fix direction is quantized or streamed syncs; that's on the to-do list, not in this post.
DiLoCo holds flat from gigabit down to 50 Mbps while per-step syncing collapses — exactly the regime DiLoCo exists for. [measured] The failure at 10 Mbps is the instructive part: the pseudo-gradient transfer saturates the link so thoroughly that torchft’s own coordination traffic can’t get through, and the quorum times out mid-sync. A fault-tolerant system has a control plane that needs bandwidth too, and starving it is its own failure mode.
Then I rented a GPU. A home RTX 3060 and a Virginia RTX 4090, joined over a Tailscale mesh across the open internet, trained as one DiLoCo cluster — and the model digests came out bit-identical across the WAN, the first time I’d seen the whole stack work between two machines in different states. Total spend across every cloud experiment, including the false starts: $3.12. [single-run.] But scaling that up surfaced the finding that names the milestone.
Connectivity is not coordination — the same network produces both of these outcomes. DiLoCo workers sync after every H *local* steps, which means they sync at whatever wall-clock moment they happen to finish those steps. Top: when the workers are well-matched and started together, their H-boundaries line up, both arrive at the barrier at the same time, and you get one shared all-reduce and one identical model — matching digests. Bottom: when the workers start minutes apart or run at different speeds (a 4090 is ~4× a 3060), each one reaches its boundary alone, finds no peer waiting, and — with the minimum-quorum size set to one — commits *by itself*. The cluster silently decays into N independent solo runs that each converge fine, but to different optima; the cross-region digests did not match. Both nodes reported perfect health the entire time. Nothing was down. They simply weren't training together, and no liveness check would ever tell you so. Genuine collaboration needs either aligned starts and matched speeds, or a hard barrier that makes fast workers wait — which has its own cost, measured next.
This is the one that changed how I think about the whole problem. With the minimum quorum size set to one, two healthy, fully-connected nodes that hit their sync boundaries at different wall-clock times each commit alone, and the “cluster” quietly becomes two independent solo runs converging to different models — while every health check stays green. Connectivity is not coordination. The fix is a real barrier (require at least two participants per sync), but a barrier forces fast nodes to wait for slow ones, and that cost is exactly what the last milestone had to confront at scale.
M5 — 32 replicas, one box, and “liveness ≠ participation”
torchft’s framing is ~30 replica groups. I wanted to match that scale — but the unknowns at N = 32 weren’t about geography, which M4 had already settled; they were about coordination. Does the lighthouse stay sane managing 32 members? Does a 32-way all-reduce form and commit? Does the barrier from M4 hold without falling over? Every one of those questions answers on a single machine, for $0, with chaos I control precisely and no cloud nodes to herd. So M5 ran 32 replica groups as CPU processes on a single 16-core Ryzen box, each in its own network namespace, with a 3.3M-parameter model — small because thirty-two full models don’t fit commodity RAM, and the storm exercises the coordination machinery, which doesn’t care how big the model is.
I built up to it on a de-risk ladder — N = 4, then 8, then 32 — and it paid for itself immediately. The “barrier OOM” that had spooked me in M4 turned out to be an artifact: orphaned processes from repeated dirty relaunches piling up on a machine I hadn’t cleaned, not a real limit. On a clean box the barrier runs in about 6 GB. The lighthouse coordinated all 32 managers without complaint. The ring formed and committed. So far, so good — and then the median quorum came back at 16 of 32, and stayed there even with no faults at all.
That number is the whole milestone, so I chased it. Sixteen of thirty-two participating, fault-free, is not a fault-tolerance story — it’s a clue. The cause was CPU oversubscription: thirty-two compute-heavy processes time-slicing across sixteen physical cores get scheduled unevenly, so their step times drift apart, and at any given sync boundary only about half have arrived. Pinning each process to a dedicated core fixed it — but only after discovering that taskset silently doesn’t work here, because PyTorch and its math libraries reset CPU affinity when they import. The pin has to be set from inside the process after the libraries load, and re-asserted, because the collective operations reset it again. With that, fault-free participation jumped to the full 32.
The distinction that names this milestone, measured over the full storm. The filled band is *liveness* — how many of the 32 replicas are alive and training at each moment — and it rides high, around 30, dipping only briefly when a cluster of faults lands. The bold line below it is *participation* — how many replicas actually made it into each sync's quorum — and it sits at about 16, half the cluster, the entire run. The red ticks along the bottom are the kills. The gap between the band and the line is the finding: under a steady fault rate, "alive" and "contributing to this sync" are simply different numbers. Almost everyone is up and working; only about half are phase-aligned enough at any given barrier to be counted in it, because every fault reconfigures the quorum and knocks the survivors' sync timing out of step, and at 125 faults an hour the cluster never fully re-aligns. The honest way to report a run like this is all three numbers — cluster size (32), live replicas (~30), per-sync participation (~16) — because collapsing them into one hides the tax that churn imposes on coordination.
That gap — ~30 alive, ~16 participating — is the second distinction, and it’s the one I’d most want a reader to take away. Under a steady fault rate, the workers stay overwhelmingly alive, but each fault reconfigures the quorum and jostles the survivors’ sync timing out of phase, and at 125 faults an hour they never fully settle back into lockstep. So a snapshot finds most of them up and training, but only about half aligned at any given barrier. Cluster size, live count, and per-sync participation are three different numbers, and a single “healthy: 32/32” would have lied to me about all of it. (Pinning lifts the fault-free participation to 32 and the commit reliability to 97%, but under the storm, participation is governed by churn, not the scheduler — so it sits near 16 regardless.)
None of which stopped the cluster from doing its job:
Recovery latency across all 27 executed kills, as cumulative distributions. The left curve, T_resume, is how long until the *survivors* commit their next sync after a kill — a median of 57 seconds, the cluster barely breaking stride. The right curve, T_back, is the harder bar: how long until the killed replica is fully relaunched, has pulled fresh state from a peer, and is committing as a member again — a median of 149 seconds, with the long tail being processes unlucky enough to be relaunching into the teeth of the oversubscribed CPU while everything else competes for the same cores. Every one of the 27 kills recovered; none required a human. Read together with the previous figure, this is the actual fault-tolerance claim: the cluster stays alive and keeps making correct progress through a fault every twenty-nine seconds, and the loss — measured separately — falls 10.8 to 4.3 straight through all of it, with zero out-of-memory deaths across the entire run.
The final tally for the canonical pinned run: 97.7% step efficiency against the matched fault-free baseline, 97% of sync attempts committing, all 27 kills recovered (T_back median 149 s), the loss descending 10.8 → 4.3 monotonically through 28 kills, and zero out-of-memory deaths over the whole thirty minutes. [measured / derived.] That’s the animation at the top of this post — every cell a replica, color-coded by state, the quorum and the loss tracked live, all of it reconstructed from the run’s own telemetry.
Process lessons (the stuff between the milestones)
A build log owes you the texture, not just the results. The things that actually cost time:
- Assume the control channel is unreliable, including the one you’re typing into. My laptop-to-trainer link flapped under load and eventually died outright. Everything long-running lives in
tmuxon the worker; every transfer is anrsyncin a retry loop; and I built a runner that retries across link flaps and falls back to a second network path. Never hand-drive a 45-minute job over a bare SSH session. pkill -fis a loaded gun. A pattern that matches your training command also matches the SSH session running it — I killed my own workers with diagnostic commands more than once. Scope kill patterns to a run ID and put them in a script, never the command line.- At scale, watch the aggregate, not the nodes. The thing that made the cloud milestone expensive in attention was hand-inspecting individual machines. The thirty-two-node storm was only tractable because I monitored one summary — derived from the lighthouse and the telemetry — instead of thirty-two terminals.
- Cost discipline is a habit, not an afterthought. Every cloud experiment, including a dozen false-start instances, totaled $3.12, because instances get destroyed the moment they’re done and a ledger tracks every cent.
The Evidence Ledger
Distributed-systems claims oversell as easily as benchmarks, so here is every load-bearing number, sorted by how I actually know it. Measured means read directly from a run’s telemetry. Derived means composed from measured primitives. Single-run means one un-repeated result.
| Claim | Value | Evidence |
|---|---|---|
Outer-optimizer momentum recovers through kill -9 |
bit-identical digests, every post-recovery sync | measured (M0.5, M2) |
| Single-fault recovery latency | T_resume 5.0 s, T_rejoin 54 s | measured (M2) |
| DiLoCo parity vs baseline | +2.8% (H=25) … +9.4% (H=500) loss | measured (single seed/H, outer-lr untuned) |
| Communication reduction | exactly H-fold, measured within a few % | measured (veth counters) |
| Storm step efficiency (2 replicas) | 88.2% / 85.0% at 69 / 85 faults·hr⁻¹ | derived (chaos rate ÷ fault-free rate) |
| Throughput-healthy eval regression, and its fix | 2.4 → 4.0 then fixed to monotonic | measured (M3, with/without checkpoints) |
| WAN throughput, DiLoCo vs per-step | 27–37k vs 5.3k→0.9k tok/s; both DNF at 10 Mbps | measured (netem sweep) |
| Cross-region cloud trains as one cluster | bit-identical digests over the internet | single-run ($3.12 total cloud) |
| Connectivity ≠ coordination | solo commits, divergent digests, all nodes healthy | measured (M4) |
| N=32 step efficiency under 125 faults·hr⁻¹ | 97.7% of fault-free; 27/27 kills recovered | measured / derived (M5) |
| Liveness vs participation under churn | ~30/32 alive, ~16/32 per sync | measured (M5) |
| Loss through the N=32 storm | 10.8 → 4.3 monotonic, 0 OOM | measured (M5) |
A caveat worth stating loudly: the convergence numbers (M0, M1) are single-seed where they’d ideally be multi-seed, and the cloud results (M4) are single runs, not distributions — they’re tagged accordingly. The fault-tolerance and coordination findings — the digests, the regression, the participation gap — are the load-bearing ones, and those are measured directly off telemetry I can hand you. I also kept a separate log of the torchft friction I hit along the way (an address-binding bug that breaks recovery behind NAT, a too-short default quorum timeout, the undocumented standalone setup); those are candidate upstream contributions I intend to raise with the project after this writeup, framed as questions rather than claims.
What I Learned
-
Momentum survives recovery — and everything depended on that holding. The single most consequential measurement in the project was the earliest: that the outer optimizer’s momentum comes back bit-exact through a real kill, with no checkpoint. If that digest hadn’t matched, every later result would have been built on sand. When you’re testing a system, find the load-bearing assumption and attack it first.
-
Measure progress, not throughput — they diverge silently, and the divergence is the research. The eval-loss regression in M3 was invisible to every operational metric: syncs were committing, efficiency was 87%, the cluster looked perfectly healthy while the model rotted. Throughput tells you the machine is busy; it does not tell you the work is good. The most valuable thing I built was the telemetry that let me watch the model’s quality in real time, because that’s where the failure hid.
-
Cluster size, live replicas, and per-sync participation are three different numbers. Collapsing them into one “healthy: N/N” hides the entire cost that churn imposes on coordination. At scale, almost everyone is alive almost always — and only some of them are actually in any given sync. If you report one number, report the one that’s doing the work: participation.
What I’d Build Next
In rough order of value:
- An alignment mechanism for the participation gap. A short quorum-gather window, or re-phasing replicas’ sync boundaries after a reconfiguration, so churn stops scattering them out of step. This is the direct lever on the ~16/32 number, and it’s the most interesting open problem the project surfaced.
- Quantized or streamed syncs, against the 10 Mbps cliff. The control-plane starvation that kills the cluster at 10 Mbps is a bandwidth problem with a known shape: shrink the pseudo-gradient payload (it’s full fp32 today) or stream it in fragments so heartbeats can interleave. The reward is collaborative training over genuinely bad links.
- Larger N on real multi-host hardware. M5’s 32 replicas shared one machine’s sixteen cores, which is what produced the oversubscription story. The same harness across several physical machines would separate the coordination findings from the scheduling artifact and push toward torchft’s actual scale.
- The torchft friction, upstream. The address-binding bug, the quorum-timeout default, the standalone-setup gap — written up as issues and, where I have a clean fix, pull requests. After this post, and as questions first.
- Independent reproduction. The repo is built for it — every run writes the JSONL these figures are reconstructed from, and the de-risk ladder is scripted. The real bar is someone else killing their own nodes and reading the same recovered digests.
Acknowledgments
This stands on specific prior work: the DiLoCo paper that made low-communication training a real algorithm, and Meta’s torchft, which turned it into running fault-tolerant infrastructure and whose issue #171 framed the question I spent six milestones answering. The model is a nanoGPT-class network trained on TinyStories; the animations and live dashboards lean on Rich, plotext, asciinema, and agg; the WAN realism comes from Linux tc/netem and Tailscale; the cloud GPUs were rented from Vast.ai for the price of a sandwich.
The full source — every milestone’s run data, the chaos harness, the telemetry pipeline these figures are built from, and the dated build log every anecdote here came from — is on GitHub. If you’d argue with any number in this post, the JSONL is right there to argue with. That’s how the next iteration gets honest.