Part 1 of the Compiler Design & Implementation series. Scanning is the first stage of the three-part process that the compiler’s front end uses to understand the input program. It’s also known as lexical analysis.
The scanner reads a stream of characters and produces a stream of words, each tagged with its syntactic category. It is the only pass in the compiler that touches every character of the source program — so we optimize for speed.
What This Post Covers
- Lexical Analysis — What the scanner does and why it’s the first phase of compilation
- Recognizers & Finite Automata — The formal machinery behind word recognition
- Regular Expressions — The concise notation for specifying token patterns
- Implementation — A hand-written scanner for C0 in Rust
Tokens and Microsyntax
For each word in the input, the scanner determines if the word is valid in the source language and assigns it a syntactic category — a classification of words according to their grammatical usage (think: part of speech).
A token is a tuple: (lexeme, category).
Microsyntax specifies how to group characters into words, and conversely, how to separate words that run together. A keyword is a word reserved for a particular syntactic purpose that cannot be used as an identifier.
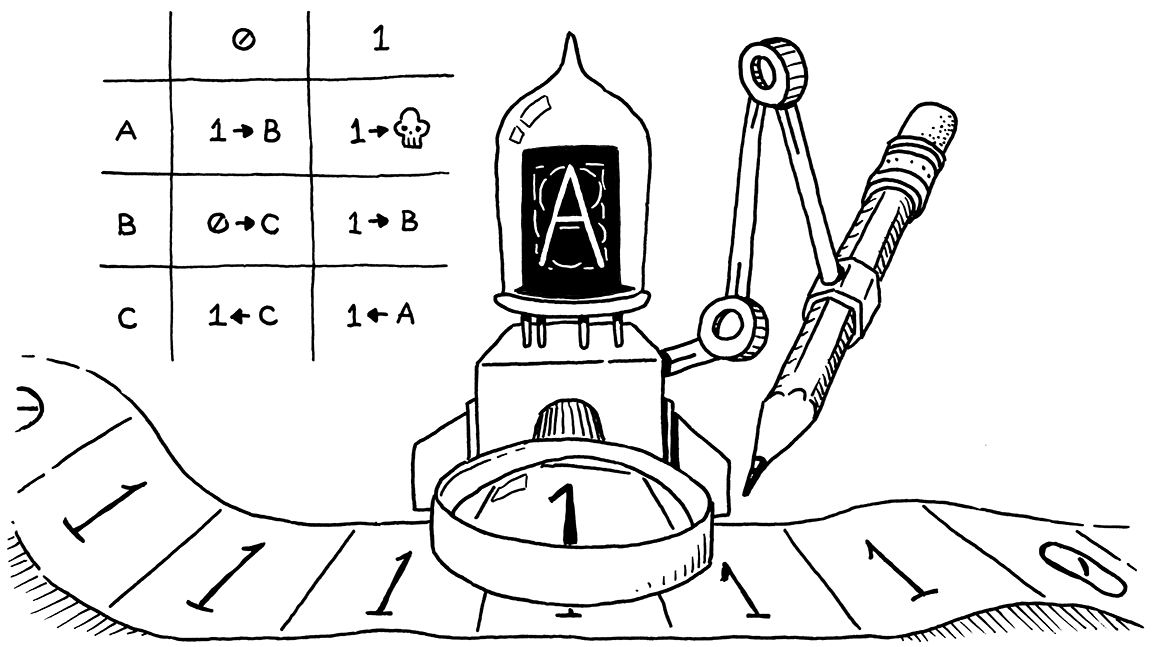
Recognizers
Scanners are based on recognizers — programs that identify specific words in a stream of characters. These recognizers simulate deterministic finite automata (DFAs).
Transition diagrams serve as abstractions of the code required to implement recognizers. They can also be viewed as formal mathematical objects called finite automata.
Formal Definition
A finite automaton (FA) is a five-tuple (S, Σ, δ, s0, SA) where:
| Symbol | Meaning |
|---|---|
| S | The finite set of states, including the error state se |
| Σ | The finite alphabet (the union of edge labels in the transition diagram) |
| δ(s, c) | The transition function — maps each state s ∈ S and character c ∈ Σ into a next state |
| s0 ∈ S | The designated start state |
| SA ⊆ S | The set of accepting states (double circles in the diagram) |
This five-tuple is equivalent to the transition diagram; given one we can easily recreate the other.
Acceptance
An FA accepts a string x if and only if, starting in s0, the sequence of characters in x takes the FA through a series of transitions that leaves it in an accepting state when the entire string has been consumed.
More formally, the FA (S, Σ, δ, s0, SA) accepts x if and only if:
\[\delta(\delta(\ldots\delta(\delta(s_0, x_1), x_2), x_3)\ldots, x_{n-1}), x_n) \in S_A\]Two cases indicate the input is not a valid word:
- The error state se — a sequence of characters isn’t a valid prefix for any word in the language
- The FA reaches the end of the input while in a non-accepting state
Cyclic vs. Acyclic Transition Diagrams
Any finite set of words can be encoded in an acyclic transition diagram. Certain infinite sets — like the set of all integers or identifiers in Java — give rise to cyclic transition diagrams.
A simplified rule for identifier names in Algol-like languages (C, Java, etc.): an identifier consists of an alphabetic character followed by zero or more alphanumeric characters.
A cyclic transition diagram recognizing identifiers: an alphabetic character followed by zero or more alphanumeric characters.
Regular Expressions
Transition diagrams can be complex and nonintuitive, so most systems use a notation called regular expressions (REs). Any language described by an RE is a regular language.
The set of words accepted by an FA, F, forms a language denoted L(F). An RE describes a set of strings over an alphabet Σ plus ε (the empty string).
Three Fundamental Operations
- Alternation — r ∣ s is the union: {x ∣ x ∈ L(r) or x ∈ L(s)}
- Concatenation — rs contains all strings formed by prepending a string from L(r) onto one from L(s)
- Kleene Closure — r* contains all strings consisting of zero or more words from L(r)
Precedence order: parentheses > closure > concatenation > alternation
Positive closure r+ is just rr* — one or more occurrences of r.
RE Examples
1. Identifiers (Algol-like languages):
([A...Z] | [a...z])([A...Z] | [a...z] | [0...9])*
Most languages also allow special characters like _, %, $, or &. If the language limits identifier length, use a finite closure.
2. Unsigned integers:
0 | [1...9][0...9]*
The simpler spec [0...9]+ admits integers with leading zeros.
3. Unsigned real numbers:
(0 | [1...9][0...9]*)(ε | .[0...9]*)
With scientific notation:
(0 | [1...9][0...9]*)(ε | .[0...9]*)E(ε | + | -)(0 | [1...9][0...9]*)
4. Quoted character strings in C:
"(^(" | \n))*"
The complement ^c specifies Σ - c. This reads as: double quotes, followed by any number of characters other than double quotes or newlines, followed by closing double quotes.
5. Comments:
Single-line (//):
//(^\n)*\n
Multiline (/* ... */) — not allowing * in comment body:
/*(^*)**/
Allowing * in the body (more complex due to multi-character delimiters):
/*(^* | *+^/)**/
An FA recognizing multiline comments (/* ... */) that allows * within the comment body.
6. Registers (for a processor with ≥32 registers):
r([0...2]([0...9] | ε) | [4...9] | (3(0 | 1 | ε)))
For “unlimited” (99999) registers: r[0...9]+
Cost of Operating an FA
The cost of operating an FA is proportional to the length of the input, not to the complexity of the RE or the number of states. More states need more space, but not more time. In a good implementation, the cost per transition is O(1).
The build-time cost of generating the FA for a more complex RE may be larger, but the operational cost stays constant per character.
Closure Properties
REs are closed under alternation, union, closure (both Kleene and finite), and concatenation. This means we can take an RE for each syntactic category in the source language and join them with alternation to construct an RE for all valid words — and the result is still a regular language.
Why Hand-Write a Scanner?
Tools like Flex and re2c can generate scanners automatically from regular expression specifications. But hand-writing a scanner teaches you what these tools do under the hood, gives you full control over error handling and performance, and — for simple languages — often produces cleaner, faster code than generated alternatives.
What’s Next
In Part 2: Parsers, we’ll move from the flat stream of tokens produced by the scanner to building structured representations of the program — parse trees and abstract syntax trees — using context-free grammars and recursive descent parsing.